Phaser Platformer Series: 24 Tilemap Objects
posted on 5 September 2021
In the previous tutorial we created a basic tilemap using Tiled and loaded it into Phaser. We stripped out most of the functionality, and in this tutorial we’re going to put it all back! Our tilemap is using 16px x 16px squares so we’ll stick to that to keep it looking neat. There are a few new sprites we need that are just resized verions of the old ones (16px instead of 32px). We’ll also leave out the mushroom powerup as double sizing our hero might look out of place compared to the other tiles.
Here’s what we’ll be making:
See the Pen
Phaser Platformer Series: 24 Tilemap Objects by Digitherium (@digitherium)
on CodePen.
If you are viewing on a mobile, you can open a version of it here without all the codepen chrome taking up screen space so you play it in landscape mode.
Firstly, we’ve changed some sprites so you’ll see some changes to the preload function:
this.load.setBaseURL("assets/");
this.load.image('ground', 'platform.jpg');
this.load.image('collapsing-platform', 'collapsing-platform.png');
this.load.image('collapsing-platform-hot', 'collapsing-platform-hot.png');
this.load.image('coin', 'coin-8.png');
this.load.image('hero', 'hero.jpg');
this.load.image('hero-small', 'hero-16.jpg');
this.load.image('baddie', 'baddie-16.jpg');
this.load.image('laddertile', 'laddertile.png');
this.load.image('shell', 'shell-small.jpg');
this.load.image('powerup', 'powerup-16.jpg');
this.load.image('question-mark-block', 'question-mark-block-16.jpg');
this.load.image('empty-box', 'empty-box-16.jpg');
this.load.image('dust', 'dust-small.jpg');
this.load.image('heart', 'heart.png');
this.load.image('heart-filled', 'heart-filled.png');
this.load.image("logo", "digitherium-logo.jpg");
this.load.image('touch-slider', 'touch-slider.png');
this.load.image('touch-knob', 'touch-knob.png');
this.load.image('tiles', '/map/environment-tiles.png');
this.load.tilemapTiledJSON('map', '/map/newmap.json');We’ve created some new file names for these as the previous tutorials examples still rely on the old sprites. For instance, we are still keeping our ‘coin.png’ asset for the older tutorials but the Tiled version uses ‘coin-8.png’. We’re also loading a new tilemap ‘newmap.json’;
In Tiled we need to click on the add new layer button in the layers panel and select ‘Add Object Layer’. An object layer lets us add objects to our game – as well as shapes you can click on the image button and also add tiles just like a tile layer. We’re going to use the object layer purely as information as to where to place things. Let’s start with the baddies.
Create a new object layer and name it ‘baddies’. In our tileset panel click the add new tileset and find the baddie sprite. Set it to be 16px x 16px. You can load in just this one image – it won’t actually be the sprite used in the game, we’re just going to use the positioning information, so it could be any same sized image such as the player sprite.
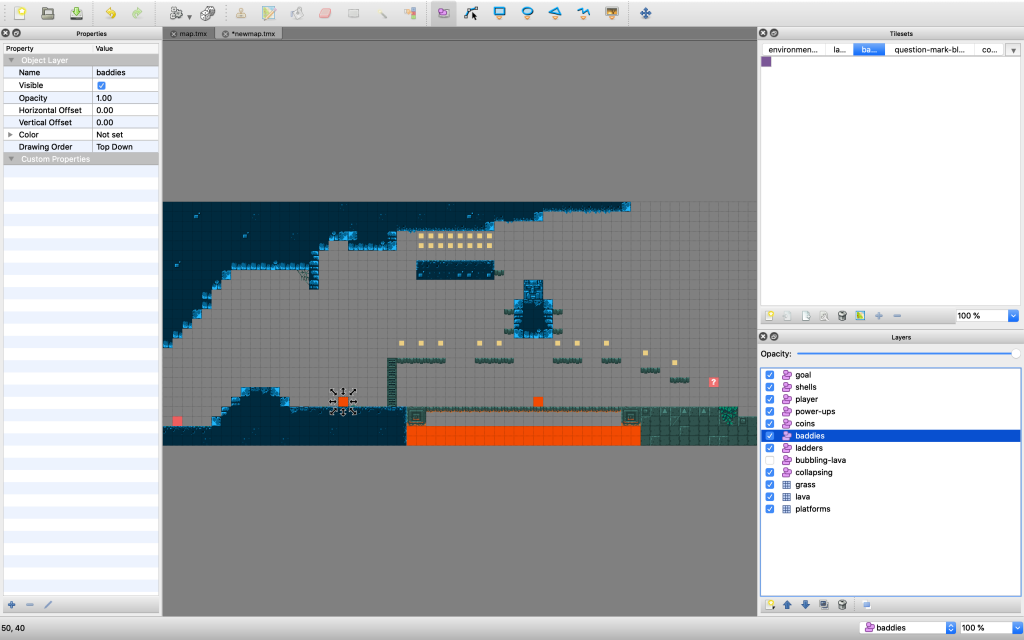
Click on the tile/image button for the layer on the top toolbar, then open the new tileset and click the baddie sprite. Then click on the map where you want the baddie to be. You may find when working on an object layer that you can place tiles anywhere and it ignores the grid. There are two ways around this – 1. hold the Cmd key (on mac, or ctrl on Windows) whilst placing a tile. 2. Go to the view menu and select ‘snap to grid’.
Once we’ve added a few baddies, we hit save and then export. We’re now ready to grab information from an object layer in our code.
Let’s create a new function called createBaddies that we will call from our create function:
gameScene.createBaddies = function() {
this.baddies = this.physics.add.group();
this.baddiesLayer = this.map.getObjectLayer('baddies');
this.baddiesLayer.objects.forEach(element => this.placeBaddies(element));
}Here we are adding a physics group that we can later use for collisions, then grabbing the layer information from our imported tilemap data. We loop through every object we find in that layer and pass it to another new function placeBaddies. To avoid any scoping issues, we are making all of these functions part of the gameScene object, which allows us to call them with the this prefix insuring that our scope is what we want it to be (the gameScene).
gameScene.placeBaddies = function(tile) {
if (tile.index != -1) {
var baddie = this.baddies.create(tile.x + (tile.width / 2), tile.y - (tile.height / 2), 'baddie');
baddie.setOrigin(.5, .5);
baddie.setCollideWorldBounds(true);
baddie.previousX = baddie.x;
baddie.body.velocity.x = this.baddieVelocity;
baddie.direction = -1;
}
}Here you can see we are creating baddies just like before. We first check that the tile is valid and has an index (i.e. it actually exists) and we are now setting the x and y position from the tile information.
Our object coordinates are slightly different from a tile layer. It takes the coordinate from the bottom left of each tile and will position the sprite origin at that point. As our sprites have their origin set to their center, then that means the center of our sprite will be placed on the bottom left of a tile position. We need to add on half the width and take away half the height of the object to get it positioned as if it were a tile. So instead of this:
var baddie = this.baddies.create(tile.x, tile.y, 'baddie');We use this:
var baddie = this.baddies.create(tile.x + (tile.width / 2), tile.y - (tile.height / 2), 'baddie');A great thing about Tiled is that we can add custom properties to each object or tile. For each baddie in tiled, we click on it to view the properties inspector and add a property called ‘maxdistance’.
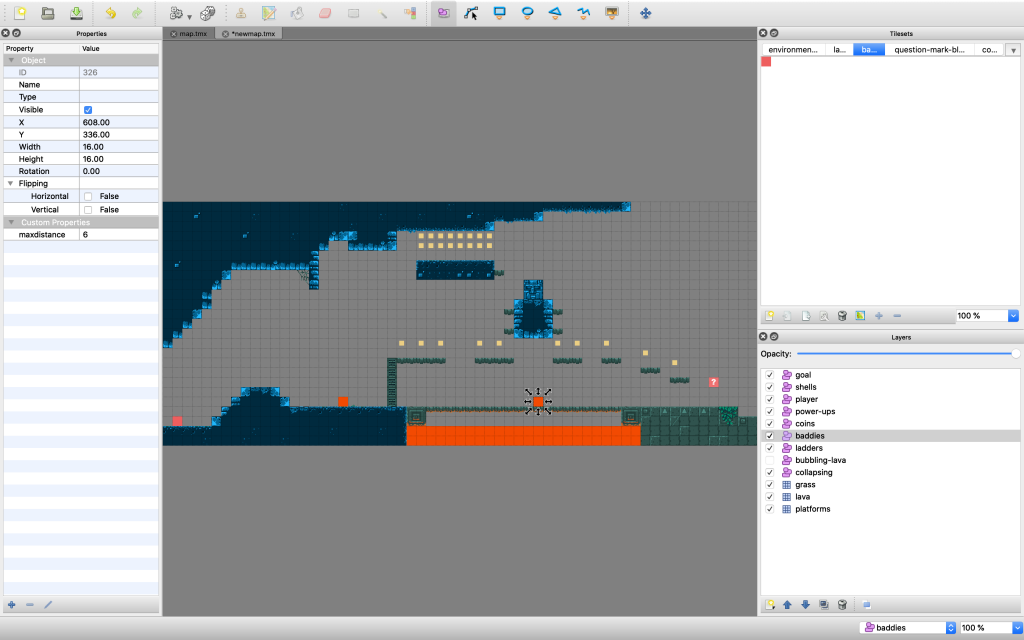
We set this to be the number of squares we want the baddie to move. We can then save, and re export our tile map and update our code to include this maxdistance to tell the baddie how far to walk:
gameScene.placeBaddies = function(tile) {
if (tile.index != -1) {
//object layer
var maxdistance = 0;
if (tile.properties != null) maxdistance = tile.properties.maxdistance * tile.width;
var baddie = this.baddies.create(tile.x + (tile.width / 2), tile.y - (tile.height / 2), 'baddie');
baddie.setOrigin(.5, .5);
baddie.setCollideWorldBounds(true);
baddie.previousX = baddie.x;
baddie.body.velocity.x = this.baddieVelocity;
baddie.maxDistance = maxdistance;
baddie.direction = -1;
}
}Here we are grabbing the maxdistance set in tiled, and multiplying it by our tile width (16px) to dynamically create the distance in pixels the baddie should walk.
In our update function we are checking when the baddie should switch direction based on this max distance. We can easily improve this by also checking for when a baddie hits a wall:
this.baddies.getChildren().forEach(function(theBaddie) {
//check if it's time for them to turn around
if (Math.abs(theBaddie.x - theBaddie.previousX) >= theBaddie.maxDistance) {
switchDirection(theBaddie);
} else {
if (theBaddie.direction == -1 && theBaddie.body.blocked.left) switchDirection(theBaddie);
if (theBaddie.direction == 1 && theBaddie.body.blocked.right) switchDirection(theBaddie);
}
}, this);If a baddie is walking left (direction = -1) we check if they are blocked left (i.e. they can no longer move left). If so, we change direction. we do the same check for a baddie walking right (direction = 1) with blocked.right. This means we can be far looser with the maxdistance property we put in, and not worry about using a number that is too high breaking anything – if the baddie walks too far and hits a wall, they’ll just turn around.
The last piece of the puzzle is updating the physics. We want to keep things neat so we call a new function from create called setupCollisions. We make this a function that belongs to the gameScene object so we call it with the this prefix and all our scoping woes are gone.
gameScene.setupCollions = function() {
//platforms / ground
this.physics.add.collider(this.player, this.ground);
this.physics.add.collider(this.baddies, this.ground);
//collapsing platforms
this.physics.add.collider(this.player, this.collapsingPlatforms, this.shakePlatform, this.checkOneWay, this);
this.physics.add.collider(this.baddies, this.collapsingPlatforms);
//lava
this.physics.add.collider(this.player, this.lava, this.playerHit, null, this);
this.physics.add.collider(this.baddies, this.lava, this.baddieDie, null, this);
//player collisions with objects
this.physics.add.overlap(this.player, this.baddies, this.hitBaddie, null, this);
this.physics.add.overlap(this.player, this.coins, this.collectCoin, null, this);
//powerups
this.physics.add.collider(this.player, this.powerupBoxes, this.hitQuestionMarkBlock, null, this);
this.physics.add.collider(this.powerups, this.ground);
this.physics.add.overlap(this.player, this.powerups, this.goInvincibile, null, this);
//ladders
this.physics.add.overlap(this.player, this.ladders, this.isOnLadder, null, this);
this.physics.add.collider(this.player, this.ladders, null, this.checkLadderTop, this);
//shells
this.physics.add.collider(this.shells, this.ground, this.shellWallHit, null, this);
this.physics.add.collider(this.player, this.shells, this.shellHit, null, this);
this.physics.add.overlap(this.shells, this.baddies, this.shellHitBaddie, null, this);
//end level square
this.physics.add.overlap(this.player, this.goal, this.finishLevel, null, this);
}In this function we’ve updated all our coliders and overlap functions so that all the callback functions are now called with a this prefix. For instance what was once hitBaddie has become this.hitBaddie. Likewise, the function declaration of hitBaddie has changed, so that instead of a stand-alone function, it is created as a function that belongs to the gameScene object. i.e. instead of this:
function hitBaddie(player, baddie) {We write this:
gameScene.hitBaddie = function(player, baddie) {This helps us keep things neat and consistent and stops us from having to worry about scope.
There were lots of functions that needed changing – playerHit, shellHit, collectCoin and many more. Anything that was stand alone has now been changed to be part of the gameScene object. That also means we no longer have to use things like call to execute functions with the correct scope. As an example, the line in hitBaddie changes from:
playerHit.call(this, player, baddie);To:
this.playerHit(player, baddie);Which is much simpler to understand. The downside is there are loads of this keywords flying around, but it is at least explicit – we know when we see a function prefixed with this. that it belongs to this scene.
Now we have a more consistent coding style we can go ahead and add the other object layers. The same process we just used for baddies and be repeated (both in Tiled visually and codewise in Phaser) for each type of game object.
- A new Object layer is create in Tiled
- Objects are positioned and the file is saved and exported
- We then loop through each object layer and add the sprites to our game programmatically.
With all the different types of game object, our create function ends up looking like this:
gameScene.create = function() {
this.addLogo()
//main tile map for static elements
this.setupTileMap();
//game objects from object layers in tiled
this.createCoins();
this.createLadders();
this.createBaddies();
this.createCollapsingPlatforms();
this.createPowerups();
this.createShells();
this.createPlayer();
this.createFinish();
this.setupControls();
this.createHUD();
this.createEmitter();
this.setupCamera();
this.setupCollions();
}All of the game object functions to create baddies, ladders, coins, etc are very similar. The only slight difference is some of the objects don’t need to be affected by gravity, like coins. The coins groups is created using a staticGroup:
this.coins = this.physics.add.staticGroup();Whilst the baddies are a regular physics group affected by gravity:
this.baddies = this.physics.add.group();In previous examples, we only ever had one ladder. We can now have multiple, so we need to amend the code slightly. When ascending or descending we centered the player horizontally on the ladder to make it neater and this was done like so:
//when moving vertically we want the player perfectly lined up
this.player.x = this.ladder.x;We could do this, as this.ladder was a variable and a one off. Now there are multiple ladders, we must store which one we are currently on. We do that in isOnLadder:
gameScene.isOnLadder = function(player, ladder) {
//set ladder flag to true and remove gravity but only if not at the top of the ladder
if (Math.floor(player.y) + (player.height / 2) > ladder.y - (ladder.height / 2)) {
this.onLadder = true;
//remember this ladder
this.currentLadder = ladder;
player.body.setAllowGravity(false);
}
}Here we are storing the ladder we are on in this.currentLadder. Then in our update code where we horizontally center the player upon climbing a ladder, we can reference this variable:
//when moving vertically we want the player pefectly lined up
this.player.x = this.currentLadder.x;Some of the collapsing platforms are near the lava, and our tileset has some really nice tiles where the glow of the lava is visible. We could create a separate object layer for these two types of tiles but functionality wise they are identical.
To save repeating our saves code-wise, we can use a custom property again in Tiled. When using a lava version of the collapsing platform tile we add a property ‘ishot’ and set it to 1. Again, the actual sprite/tile we are using in Tiled doesn’t actually matter on an object layer. It would make sense to use the standard collapsing tile image for standard collapsing tiles, and the glowing lava one for ones near lava – it would certainly make it clearer when we look at the Tiled layout exactly what the loaded level is going to look like. We don’t have to do that though – we can use the same tile for all of them and use the custom property to load a different sprite based on that in our code. We’re just using the positioning information from Tiled, what sprite we actually place in that spot is up to our code.
We can check if the collapsing platform is a special lava one like so:
gameScene.placeCollapsingPlatforms = function(tile) {
if (tile.index != -1) {
//two sprites for this type of tile, one with lava one without
var sprite = "collapsing-platform";
//check for 'ishot' property on each tile
if (tile.properties != null && tile.properties.ishot) sprite = "collapsing-platform-hot";
this.collapsingPlatforms.create(tile.x + (tile.width / 2), tile.y - (tile.height / 2), sprite);
}
}If the ‘ishot’ property exists on a collapsing tile object then we know to load in a different sprite.
Whilst we are placing all these game objects using object layers, we may as well set up the player this way too, instead of just hardcoding their position.
We need an object layer in Tiled with the tile placed where we want it. Then we can create our player using this info and positioning them in the right spot:
gameScene.createPlayer = function() {
this.playerLayer = this.map.getObjectLayer('player');
this.playerLayer.objects.forEach(element => this.placePlayer(element));
}createPlayer calls the function this.placePlayer for every player object it finds. Obviously, we only want one player object, so we will only add one object in Tiled on that layer. Then we can create our player exactly how we used it, except instead of a hardcoded coordinate it uses the object coordinates from Tiled:
gameScene.placePlayer = function(tile) {
this.player = this.physics.add.sprite(tile.x + (tile.width / 2), tile.y - (tile.height / 2), 'hero-small');
this.player.setOrigin(.5, .5);
...Finally, we’ve added an end of level square. A place that when the player get to it, ends the game. An object layer called ‘goal’ was create in Tiled. In the create function we call createFinish:
gameScene.createFinish = function() {
this.goal = this.physics.add.staticGroup();
this.goalLayer = this.map.getObjectLayer('goal');
this.goalLayer.objects.forEach(element => this.placeGoal(element));
}This is turn calls placeGoal when we take the coordinates from Tiled and position both an invisble tile and an emitter:
gameScene.placeGoal = function(tile) {
if (tile.index != -1) {
var finish = this.goal.create(tile.x + (tile.width / 2), tile.y - (tile.height / 2), 'hero-small');
this.goal.setVisible(false);
this.goalParticles = this.add.particles('coin');
this.goalEmitter = this.goalParticles.createEmitter({
x: tile.x - (tile.width / 2),
y: tile.y - 2,
lifespan: 1500,
speedY: { min: -60, max: -20 },
speedX: { min: -40, max: 40 },
angle: { min: 180, max: 360 },
gravityY: -20,
scale: { start: 0.8, end: 0 },
alpha: { start: 1, end: 0 },
blendMode: 'SCREEN'
});
}
}The whole physics group goal is set to be invisible. We are just using it for a collision to test when the player has hit it. We add an emitter to draw attention to the square and to try and make it an obvious place to try and reach in the game.
We add a collider between the player and that end square that will end the game in our setupCollions function:
this.physics.add.overlap(this.player, this.goal, finishLevel, null, this);Upon collision that calls this function:
function finishLevel(player, goal) {
game.scene.switch('game', 'endScreen');
}A lot of big changes happened in this one. You can see how tilemaps really open up a ton of possibilities for level design. It just really expands the scope and size of a game and lets you think visually.
You can hopefully also see how the growing complexity of the game is pushing us towards a stricter coding style. There is a large gulf between the really simple Phaser examples in the getting started docs and the more modern object-orientated javascript code you often see in working Phaser games. My aim with these tutorials was to try and show how you naturally end up in that place once a game is complicated enough. As the code goes far beyond just the 3 main phaser functions you really start to need a decent structure and some consistency.
Now that we have tilemaps working and our functionality has scaled up to with it we can look at some more juicing. The game is functional, and thanks to the tilesets it’s looking way better. With these solid foundations, we can start to add more sparkle. That’s coming soon.
chromeless mobile version
view all the code on codepen
download the source on github.